
Le contenu dupliqué est l’un des nombreux obstacles au référencement d’un site internet. Il existe deux types de contenus dupliqués : le contenu dupliqué interne et le contenu dupliqué externe. On parle de contenu dupliqué interne lorsqu’un même contenu se retrouve sur deux pages d’un même site. C’est notamment le cas quand on utilise le fonctionnement par défaut des archives de catégories sur WordPress. Le contenu dupliqué externe correspond à la reprise du contenu d’un site web par un autre site. Cet article se consacre exclusivement au contenu dupliqué externe. Nous allons vous expliquer comment le détecter et comment y remédier. Cet article fait partie de notre série d’articles sur la création de contenu.
Qu’est-ce que le contenu dupliqué ?
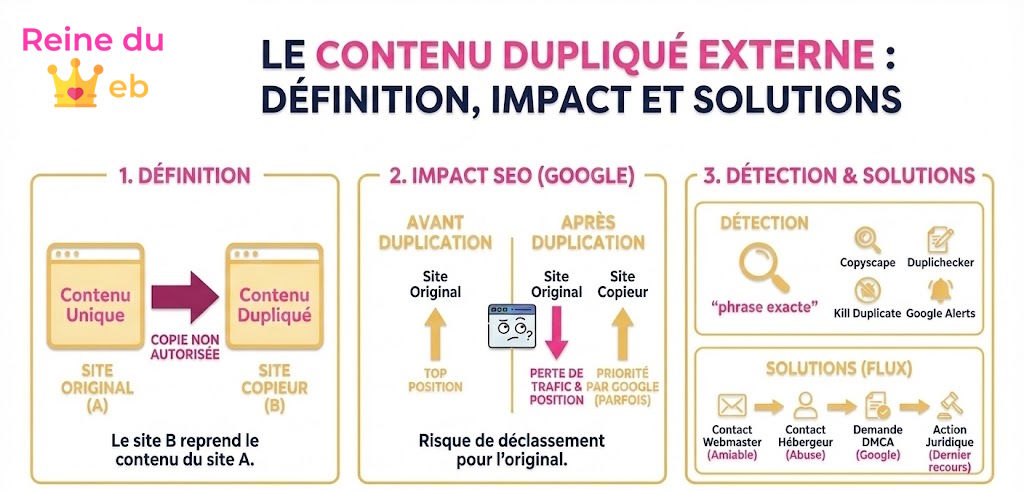
En référencement naturel, la duplication de contenu s’applique à tous les types de contenus : textes et images. Google sait tout à fait comparer les images et reconnaître lorsque deux images sont identiques. C’est pareil pour les textes. Les moteurs de recherche savent détecter lorsqu’un texte est trop semblable à un autre texte. Des algorithmes mesurent le taux de similarité. Donc pour résumer, le contenu dupliqué, c’est la copie de contenu à l’identique.
Quel est l’impact du duplicate content sur le référencement organique ?
L’impact va grandement varier d’un site à un autre en fonction de différents facteurs comme son degré d’autorité aux yeux de Google. Ce qu’il faut savoir, c’est que dans le monde de Google, celui qui publie un contenu en premier n’en obtient pas forcément la paternité ad vitam æternam. Bien au contraire, l’expérience montre que si un site B avec une popularité plus forte que le site A republie le contenu du site A quelques années après la publication originale sur le site A alors dans de très nombreux cas, c’est le site B que Google positionnera sur ce contenu et le site A disparaîtra des classements pour ce contenu. Cela pourra également avoir un impact sur le référencement global du site A, en particulier si de nombreuses pages de son site subissent le même sort. Le fait qu’un site ne contienne pas un contenu 100% original est un signal impactant la qualité perçue par le moteur de recherche.
Comment Google justifie un tel fonctionnement ?
Le fonctionnement actuel illustre un souci au niveau de l’algorithme. On comprend aisément que Google ait des difficultés à attribuer la paternité d’un contenu en fonction de son antériorité car cela nécessiterait de stocker tous les pages du web avec leur historique et de faire ensuite des comparaisons bien plus conséquentes que ce qui est fait avec l’index actuel beaucoup plus limité. Donc il est probable que des considérations financières et techniques soient à la base de ce fonctionnement. Les ressources pour calculer et comparer sont très chères. En matière de contenu identique, cela ne rapporterait pas grand chose à Google si ce n’est le fait d’être plus juste et pertinent. Le fonctionnement actuel basé sur l’autorité est plus simple du point de vue algorithmique et surtout moins coûteux en ressources.
Google a été interrogé à de nombreuses reprises sur ce sujet car c’est un problème récurrent en matière de référencement naturel. Les réponses sont toujours restées assez évasives. En décembre 2020, John Mueller (expert en charge des relations avec les webmasters chez Google) s’est exprimé à ce sujet et a indiqué qu’il était compliqué de déterminer la source originale d’un contenu et que dans certaines situations, le site reprenant le contenu pouvait y apporter une certaine valeur ajoutée, notamment avec des éléments de contexte ou une analyse complémentaire (voir la citation ici). Cette explication est tout à fait audible. Cependant, elle se heurte aux situations où Google déclasse une page originale pour favoriser une page contenant du contenu plagié.
Pourquoi certains sites utilisent du contenu dupliqué ?
On retrouve 4 grands types de situations :
- Le site légitime qui reprend une photo sur un autre site pour illustrer un article. Souvent, l’éditeur pris la main dans le sac se justifie en disant que c’est un jeune stagiaire qui a mal fait son travail mais que fort heureusement il n’est plus là. Cette situation se termine en général par le retrait de l’image, l’ajout d’un lien de crédit et même parfois une transaction financière.
- Le site à vocation SEO qui reprend un texte partiellement ou en totalité. Le but est de faire du remplissage de façon rapide. Souvent des rédacteurs low cost sont employés et pour gagner leur vie correctement, ils sont obligés de produire des textes en grande quantité ce qui implique de recourir au plagiat ou à la paraphrase. Là, c’est souvent un peu plus compliqué car il faut arriver à contacter le webmaster qui est en général bien caché.
- Le site de Spamdexing qui reprend du contenu en masse, le mixe en prenant une phrase, voire un morceau de phrase, dans un article et une autre sur un autre site. Le but est de produire très rapidement des sites comprenant des centaines voire des milliers de pages de façon automatique. Cela ne prend que quelques minutes avec les outils adaptés de génération de contenu. Ce contenu est ensuite cloaké : Google voit le contenu et positionne la page à partir de ce contenu mais le visiteur est redirigé vers un site d’e-commerce. C’est bien entendu contre les guidelines de Google et parfaitement illégal dans de nombreux cas. Dans cette situation, retrouver le propriétaire du site demande beaucoup de patience.
- Le site piraté : un site légitime a été piraté. Le contenu original est souvent toujours en place mais des milliers de pages de contenu auto généré ont été ajoutées. Là encore, un cloaking est souvent en place pour rediriger le visiteur vers un site tiers. Ce problème touche de nombreux CMS présentant des vulnérabilités de sécurité. La grande difficulté est que le webmaster n’a souvent pas conscience du piratage. En général, en l’informant, il fait disparaître le contenu reproduit en quelques heures.
On le voit, il y a un gap important entre la personne qui reprend une photo de façon isolée et le professionnel du spam qui crée des sites à la chaîne avec des milliers de pages de contenu généré automatiquement à partir de contenu tiers ou encore les hackers.
Comment détecter le contenu dupliqué ?
La détection du contenu dupliqué prend du temps et nécessite des outils. Si vous n’avez pas envie de payer, vous avez la méthode manuelle qui consiste à entrer chaque phrase d’un article entre guillemets dans Google. Cela va avoir pour effet de faire une recherche exacte et Google va vous renvoyer toutes les pages présentant ce contenu. C’est facile à faire pour quelques lignes mais impossible pour un site entier. Dans ce cas, il existe des outils automatisés. Je vous présente ici les plus fiables à la date de rédaction de l’article :
- Kill Duplicate : un outil automatique payant créé par l’excellent Paul Sanches.
- Duplichecker : un outil en ligne gratuit jusqu’à 1.000 mots.
- Antiplagiarism : un logiciel standalone qui fonctionne sur Windows.
- Vérificateur de plagiat : un autre outil en ligne gratuit très efficace.
Lorsque vous avez une page qui se positionne bien et que du jour au lendemain, elle chute brutalement sans aucune raison apparente, il peut être utile de la passer dans un outil de vérification de contenu dupliqué pour voir si elle n’a pas été copiée. Cela pourrait expliquer ce déclassement.
Que faire face au contenu dupliqué ?
Vous venez de faire la désagréable expérience de vous rendre compte que votre contenu avait été copié. Pas de panique, cela arrive à tous les sites commençant à avoir un peu de visibilité. C’est la rançon du succès. Avec l’explosion des outils de génération de contenu, c’est même devenu quasiment impossible à éviter.
A présent, vous devez agir pour faire supprimer ce contenu. Voici comment je procède habituellement :
- Remplissage du formulaire de contact présent sur le site s’il y en a un ou envoi d’un email au responsable de la publication présent sur les mentions légales.
- Si cette première étape ne donne rien, contact de l’hébergeur via le service abuse ou le service client. Pour trouver l’hébergeur d’un site, on peut utiliser un service de Whois comme celui-ci.
- Si l’échange avec l’hébergeur ne donne rien, on passe au Registrar qui est également trouvable via le Whois.
Les hébergeurs comme les registrars reçoivent des centaines de plaintes au quotidien. Certains agissent rapidement. D’autres ne feront rien tant qu’ils n’auront pas une mise en demeure voire un jugement en main. Il n’en reste pas moins qu’avec la loi LCEN en vigueur en France, l’hébergeur a une responsabilité sur les données qu’il héberge. Par conséquent, dès qu’il a connaissance d’un problème, l’hébergeur doit se montrer diligent. Dans les faits, il faut souvent lui tirer l’oreille et le rappeler à ses obligations pour qu’il commence à agir.
L’hébergeur comme le registrar ont la possibilité de couper l’accès au contenu reproduit tout simplement en bloquant l’hébergement ou le nom de domaine. C’est en général très efficace pour forcer un webmaster à agir. Après, dans certains cas, le webmaster se contentera de mettre le contenu chez un autre hébergeur ou un autre nom de domaine…
Vous avez également la possibilité de demander à Google de désindexer le contenu reproduit via une demande DMCA. C’est un processus un peu complexe où le webmaster incriminé est susceptible de faire appel. Si cela fonctionne, la page disparaîtra des résultats de recherche.
Si malgré tous vos efforts, vous n’êtes pas encore parvenu à faire retirer le contenu litigieux, il faut évaluer l’intérêt d’aller plus loin en passant via une procédure judiciaire. Cela va vous coûter : des frais d’huissier, des frais d’avocat et des frais de justice sans parler du temps passé. Il faut donc bien peser l’intérêt par rapport à l’impact. Par exemple, si la page reprise n’avait pas de trafic et ne vous rapporte rien, passez votre chemin. Si en revanche, c’était une page critique pour vos ventes, cela peut valoir le coup d’aller plus loin.
En justice, vous pourrez obtenir des dommages et intérêts. Pour les images, c’est souvent forfaitaire et assez limité. Pour les textes, cela va dépendre de l’impact. Le juge aura la main plus lourde avec une multinationale qui a repris le contenu d’un concurrent pour le parasiter qu’avec un blogueur qui a recopié quelques phrases sur un autre blog sans que cela ne porte à préjudice.
Quelques astuces pour éviter la procédure judiciaire
Un procès est souvent long et aléatoire en France. Ceux qui copient le savent bien et agissent ainsi dans une certaine impunité. Si vous n’avez pas envie de vous lancer dans une procédure juridique mais que vous aimeriez quand même trouver une solution, voici quelques astuces rapides et efficaces :
- Réécrire complètement le contenu recopié. Ainsi, vous repartirez avec un contenu original. Il ne faut pas hésiter à repartir sur une nouvelle URL, quitte à rediriger l’ancienne en 301 vers la nouvelle afin d’envoyer un signal de fraicheur à Google. C’est rageant mais c’est souvent la solution la plus rapide et la moins chère lorsque l’on n’arrive pas à contacter le webmaster.
- Suivant le type de site qui a recopié votre contenu, il peut être utile d’attendre quelques semaines avant de se lancer dans une procédure. Les sites de Spamdexing ont une durée de vie très limitée, de quelques semaines. Ils finissent toujours par disparaître de Google, souvent après avoir été signalés.
- Pour le contenu cloaké, il suffit en général de contacter le site derrière la redirection. Le propriétaire est souvent à l’origine de la technique, directement ou indirectement via un prestataire. La mise en cause peut suffire à le faire réagir.
- En regardant les liens du site copieur dans un site comme Ahrefs, on trouve souvent des informations très précieuses. Il y a parfois des commentaires laissés sur d’autres blogs, des profils de forums ou encore des articles achetés sur des sites tiers qui peuvent vous permettre de remonter jusqu’au webmaster.
Comment éviter le contenu dupliqué ?
Il n’existe hélas pas de méthode 100% efficace pour éviter le contenu dupliqué. A partir du moment où votre contenu est publié et accessible en ligne, n’importe qui peut facilement le copier.
Pour éviter la reprise automatique via un crawl de votre site, on peut néanmoins facilement agir en bloquant les robots indésirables. Sur WordPress, l’extension Stop bad bots fait très bien ce travail. Ce plugin est gratuit. Cela peut aussi se gérer manuellement en ajoutant une liste de bots indésirables sur le .htaccess de son site.
Pour la copie manuelle, vous pouvez bloquer avec un code Javascript l’usage du bouton droit de la souris. Voici le code en question :
window.addEventListener('contextmenu', function (e) {
document.body.innerHTML += '<p>Le clic droit est désactivé!</p>'
e.preventDefault();
}, false);C’est efficace contre les copieurs du dimanche mais pas contre les développeurs qui savent comment aspirer votre contenu autrement. Je n’explique pas ici comment faire mais c’est très simple et impossible à contrer.
Pour éviter la copie de masse, vous pouvez également limiter le nombre de pages visitables par une même adresse IP sur une plage de temps ou ajouter un captcha de test lorsque vous avez un doute sur une session de navigation.
Si vous achetez du contenu à des rédacteurs web, sachez que le contenu similaire, dupliqué, paraphrasé ou traduit est hélas un véritable fléau. Un tel contenu ne vous servira à rien. Pire il vous expose à des risques juridiques. Il est donc essentiel de travailler avec un rédacteur de confiance correctement payé. A ce sujet, vous pouvez faire confiance à notre service de rédaction web pour vous proposer un contenu unique, optimisé et attrayant.